The reliability pillar focuses on ensuring that a workload performs its intended function correctly and consistently when it is expected to.
Reliability/resiliency is the ability of an application or workload to avoid and recover from failure. A resilient workload is one that recovers quickly from failures to meet business and customer demand.
Ideally you do not want your applications to fail at all but failures are inevitable. The application can crush due to a bug, or you can have connectivity failures, or get a corrupted file system or database or even just accidental deletion of data. When such failures occur, you want to recover from them as quickly as possible. This is the concept behind reliability or resiliency. In other words, resiliency is what makes our applications reliable.
Availability on the other hand is how we quantify reliability. It is the percentage of time that an application is performing as expected. Poor performance indicates low availability. Uptime doesn’t necessarily translate to availability. An application might be up but not performing at an acceptable level.
When architecting for reliability, one of the most important rules to follow is to decide how much availability is needed for the workload before designing the AWS environment. Every design decision made afterwards will be tied back to the availability requirement. The decision can therefore not be made as an afterthought.
AVAILABILITY AND ANNUAL DOWNTIME
99.0% -> 3 days & 15 hours
99.9% -> 5 hours & 45 minutes
99.99% -> About 1 hour
99.999% -> 5 minutes
CALCULATING AVAILABILITY
AWS publishes the availability of its services in the Service Level Agreements (SLA) for each service. Single EC2 Instances have an SLA of 90% at the time of writing. That means each single instance has a failure rate of about 10%. To calculate for availability of our EC2 instances, we multiply the failure rates of of redundant EC2 instances subtract the product from 100%.
For example, if we have four redundant EC2 instances for our application, we:
Multiply the failure rates of the four instances
10% x 10% x 10% x 10% = 0.01%
Then subtract the product from 100%
100% – 0.01% = 99.99%
However, simply adding redundant instances is not enough to increase or maintain the availability. We need to ensure that if one instance fails, others will be spinned up to replace them. This is where an Elastic Load Balancer(ELB) comes in. The ELB will distribute traffic to the EC2 instances while continuously monitoring them. If an instance goes down the ELB will stop sending traffic to it, de-registers it and replaces it with a healthy instance.
DESIGN PRINCIPLE – LOOSE COUPLING
ELASTIC LOAD BALANCER (ELB)
Placing an ELB in front of the application servers ensures that application’s URL and the instances are loosely coupled. The users use a URL pointing to the ELB to access the application. The connection is terminating at the ELB and the ELB proxies the connection to an instance. If an instance goes down, the ELB proxies the user to a different instance.
Loose coupling improves performance by allowing you to scale components up and down independent of one another. For example, ELB allows us to upgrade instances one at a time while redirecting traffic to other instances. If an instance, fails a health check, it is automatically de-registered, terminated and replaced.
Performance and availability are linked. If an application performs really poorly it is essentially the same as being unavailable. Availability is the percentage of time the application is performing as we want it to.
SIMPLE QUEUE SERVICES (SQS)
Breaking monolithic services into microservices has the following benefits:
- It makes updating the loosely coupled services easier
- The services can be scaled independently
These services however need to talk to each other and this is where SQS comes in. The services use message queues to dump the messages and information that another service would need to process a request.
SQS is elastic and highly available.
ELASTIC CONTAINER SERVICE (ECS)
Rather than deploying microservices natively on instances, the services can be deployed in tiny little machines called containers. This decouples the services from the instances they run on.
Containers are a great way to run microservices because whatever services run inside the container is isolated from the host. So we can have multiple containers all running on a single instance without interfering with each other.
Containers make deployment and updates a lot easier. Also, having multiple containers on a single instance gives you redundancy and thus improves availability.
The Amazon Elastic Container Service (ECS) makes it really easy to use containers. In ECS, you place your instances in a cluster according to the service. Container images can be stored in Elastic Container Registry (ECR).
To launch a container you create a task definition which defines everything the container needs to run, that is, image to use, CPU & Memory allocation, instance-to-container mappings and storage mappings. ECS uses the task definitions to spawn containers on EC2 instances in your clusters. ECS can even configure an elastic load balancer to send traffic to your containers.
CONCLUSION
Availability is the percentage of time an application is performing as expected. Availability is not cheap and therefore it is important to decide the availability requirements before beginning your designing your infrastructure to meet that level of availability. Once you get the design down you can figure out the cost and then decide whether the level of availability is worth it.
Architecting is a balancing act. We are always trying to find that sweet spot where availability is acceptably high but the costs are still acceptably low.
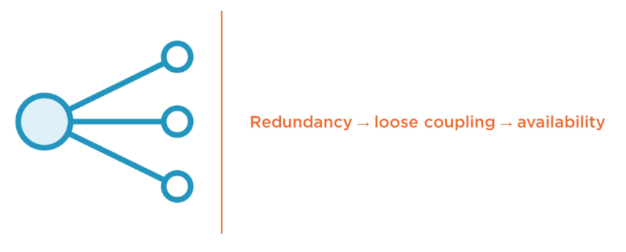
We achieve availability through redundancy and loose coupling. Loose coupling is where one component does not necessarily depend on one another. Instead one component depends on a collection of redundant components.
Loose coupling also improves performance which helps you maintain high availability.
SQS acts a go-between for loosely coupled services. A sending service places a message in a queue and a receiving service polls the queue for new messages.
There is however a limit to how much availability you can achieve because AWS imposes service limits.
The AWS Trusted advisor can be used to asses utilization against service limits.