For the last 50 days, I have always wanted to create a Kubernetes Cluster with my storage engine as Longhorn. I use MicroK8S as my Kubernetes distro. I’ll be honest with you, this was the steepest learning curve I have had to endure in my brief life thus far. Within 50 days, I have tried this, given up, tried again, given up again – repeating this for very long. I decided to move on and look for a different storage engine for K8S, but I just couldn’t leave Longhorn alone. It felt like quitting. And quitting is no good habit. I had to go back and conquer it. I have done it, and this feels like freedom!
What was the Challenge
From the beginning, my aim was simple: Create a single node kubernetes cluster using MicroK8S and Longhorn. I was able to install MicroK8S well using snap on Ubuntu 20.04. I also followed the longhorn.io docs and installed Longhorn as per the guide. But it couldn’t work. The longhorn-driver-deployer pod couldn’t start. I got a workaround on the longhorn github page but this caused a mess once the server was rebooted. After every reboot, my mount points vanished, kubelet couldn’t attach a new pod to the volumes automatically, and the data in my stateful apps was always missing. Imagine rebooting a server and finding zero databases in your MySQL database!
The fact that I also had to manually mount the pods by creating their mount points was also so off. All the while the default MicroK8S storage(microk8s-hostpath) worked so well – but its not recommended for production.
This was definitely not a production-worth setup. Attempting to run production in such a setup was a risk, of course.
So I needed a cluster which could dynamically provision persistent volumes and would restart volumes and necessary pods automatically after server reboot. I got the answers this weekend and this is how I did it
Prerequisites
- Ubuntu 20.04 server with root access
- root access to the server
- NFSv4, iSCSI initiator and snap
Procedure
1.Update repos and install required packages
For this setup, NFSv4, snap and iSCSI are required
root@vmi663745:~# apt update
root@vmi663745:~# apt install -y nfs-common snapd open-iscsi
2. Start and enable nfs-common
By default, nfs-common installs on Ubuntu 20 while masked. Unmask it first so that its possible to start and enable it
root@vmi663745:~# rm -f /lib/systemd/system/nfs-common.service
root@vmi663745:~# systemctl daemon-reload
Now, start and enable the service
root@vmi663745:~# systemctl start nfs-common
root@vmi663745:~# systemctl enable nfs-common
3. Start and enable iSCSI
What you need is iscsid (initiator) service and not open-iscsi (client) service. You may notice that trying to start open-iscsi service does not work unless you troubleshoot as show on this article
root@vmi663745:~# systemctl start iscsid
root@vmi663745:~# systemctl enable iscsid4. Install microk8s
root@vmi663745:~# snap install microk8s --classic --channel=latest
5. Enable microk8s dns (CoreDNS) and Ingress (Nginx ingress)
root@vmi663745:~# microk8s enable dns ingress
6. Install helm package manager.
root@vmi663745:~# snap install helm --classic
7. Install longhorn
Here, we use the official documentation for Longhorn 1.22 to install Longhorn
- Add the longhorn helm repo then update helm repos
root@vmi663745:~# helm repo add longhorn https://charts.longhorn.io
root@vmi663745:~# helm repo update
- Install longhorn using Helm3
root@vmi663745:~# helm install longhorn longhorn/longhorn --namespace longhorn-system --create-namespace
If the installation above fails due to kubernetes being unreachable, please check the troubleshooting section
From the docs and everything, this should be sufficient for the cluster to run. But its not. A quick view of the status of pods on the longhorn-namespace reveal that the longhorn-driver-deployer does not start well.
Check out the troubleshoot section on how to fix this and get it working well.
Troubleshooting
1. Error 1: Cannot install helm chart due to Kubernetes cluster unreachable:
Issue
Error: INSTALLATION FAILED: Kubernetes cluster unreachable: Get “http://localhost:8080/version?timeout=32s”: dial tcp 127.0.0.1:8080: connect: connection refused
Solution
Create a kubeconfig file as below
- Create a .kube folder inside home drectory
root@vmi663745:~# mkdir .kube
- Create a file called config and set its permissions
root@vmi663745:~# touch .kube/config
root@vmi663745:~# chmod 600 .kube/config
- Copy the kubeconfig onto the file as follows
root@vmi663745:~# microk8s kubectl config view --raw >> .kube/config
2. Error 2: Longhorn driver does not start
Issue 1
After successful installation of longhorn and microk8s, longhorn-driver-deployer does not start
Symptoms
- status of longhorn driver is Init:0/1 instead of Running
- status of longhorn-ui is CrashLoopBackOff. It keeps crashing and never starts

Cause
Longhorn manager and UI cannot reach the longhorn-backend service due to failed DNS resolution within the cluster.
Solution
As this is a DNS issue, you should now check the kubernetes DNS deployment, CoreDNS.
- Check the coredns pod for errors
root@vmi663745:~# kubectl logs coredns-7f9c69c78c-7dsjg -n kube-system
An output as below indicates an error in DNS resolution. CoreDNS cannot resolve dns.
.:53<br>[INFO] plugin/reload: Running configuration MD5 = be0f52d3c13480652e0c73672f2fa263<br>CoreDNS-1.8.0<br>linux/amd64, go1.15.3, 054c9ae<br>[INFO] 127.0.0.1:35941 - 17701 "HINFO IN 4725281324889338256.7661067425143258365. udp 57 false 512" NOERROR - 0 4.001660981s<br>[ERROR] plugin/errors: 2 4725281324889338256.7661067425143258365. HINFO: read udp 10.1.73.95:33226->8.8.4.4:53: read: no route to host<br>[INFO] 127.0.0.1:48855 - 60060 "HINFO IN 4725281324889338256.7661067425143258365. udp 57 false 512" NOERROR - 0 2.00083768s<br>[ERROR] plugin/errors: 2 4725281324889338256.7661067425143258365. HINFO: read udp 10.1.73.95:37897->8.8.8.8:53: read: no route to host<br>[INFO] 127.0.0.1:40459 - 55315 "HINFO IN 4725281324889338256.7661067425143258365. udp 57 false 512" NOERROR - 0 0.000247689s<br>[ERROR] plugin/errors: 2 4725281324889338256.7661067425143258365. HINFO: read udp 10.1.73.95:38124->8.8.8.8:53: read: no route to hostTo fix this:
- allow port 53 udp on the firewalls such as ufw, iptables.
- turn off apparmor
- check if the cloud provider has a cloud based server covering your server and disable it or permit necessarry traffic
- check /etc/resolv.conf and update the nameserver to public resolvable IP address e.g 8.8.8.8 or your cloud providers dns resolver
- reboot the server and recheck the logs for coredns again. the error should be resolved.
Issue 2
After the steps above, longhorn-driver changes status from Init:0/1 to CrashLoopBackOff
Cause
Longhorn fails to get the kubelet root directory. This is because kubelet root directory is not default. Checking the longhorn-driver pod error log, below error is observed.
root@vmi663745:~# kubectl logs longhorn-driver-deployer-75f68555c9-hwmwg -n longhorn-system
time="2021-10-31T21:46:05Z" level=error msg="failed to get arg root-dir. Need to specify \"--kubelet-root-dir\" in your Longhorn deployment yaml.: failed to get kubelet root dir, no related proc for root-dir detection, error out" time="2021-10-31T21:46:05Z" level=fatal msg="Error deploying driver: failed to start CSI driver: failed to get arg root-dir. Need to specify \"--kubelet-root-dir\" in your Longhorn deployment yaml.: failed to get kubelet root dir, no related proc for root-dir detection, error out"
Solution
Set the kubelet root directory on longhorn driver deployment.
For MicroK8S, kubelet root directory is /var/snap/microk8s/common/var/lib/kubelet
- Edit the longhorn-driver-deployment as follows
root@vmi663745:~# kubectl edit deployment/longhorn-driver-deployer -n longhorn-system
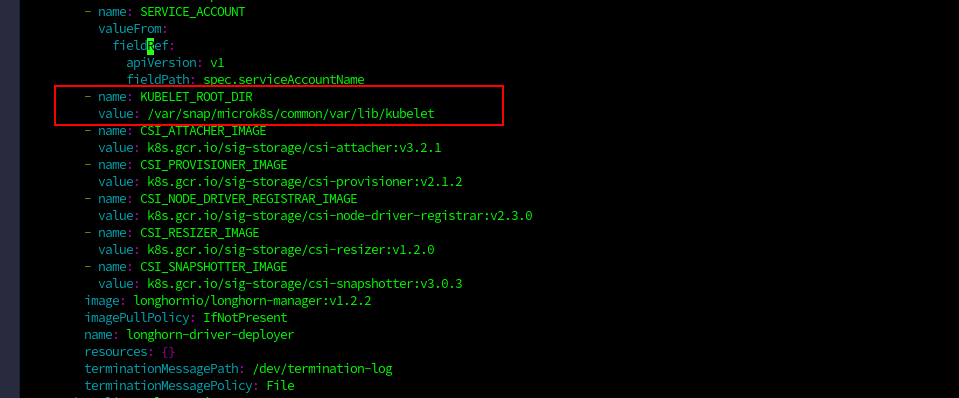
- Under the environment variables section, just above name: CSI_ATTACHER_IMAGE add the lines below then save and close
- name: KUBELET_ROOT_DIR
value: /var/snap/microk8s/common/var/lib/kubelet
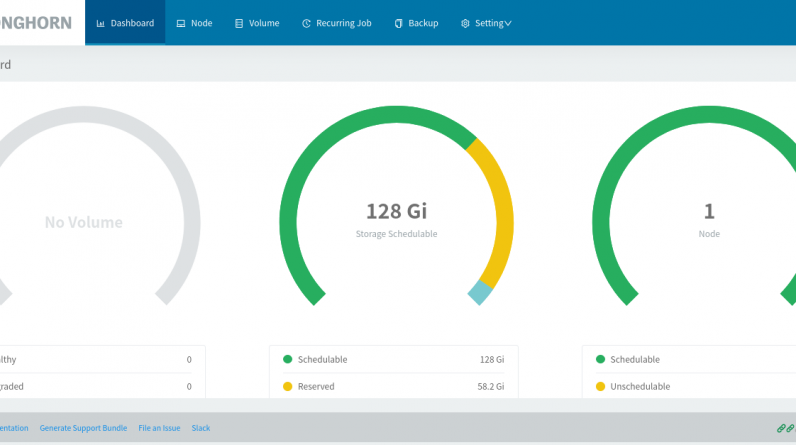
The longhorn-driver deployment deployment should then restart itself and this time, it succeeds. All pods are now online and Longhorn is ready for use. Also, after server reboot, the pods restart themselves and are in running state as expected.
Reference
- Longhorn Driver Deployer cannot start
https://github.com/longhorn/longhorn/issues/1549 - CoreDNS Fails to resolve DNS
https://github.com/projectcalico/calico/issues/3274 - Longhorn CrashLoopBackOff
https://github.com/longhorn/longhorn/issues/1861 - Microk8s kubelet root directory
https://docs.primehub.io/docs/2.7/getting_started/kubernetes_on_ubuntu_machine